 Open Data Science Europe Metadata Catalog
Open Data Science Europe Metadata Catalog
dataset
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

Regional model ICON-D2 The DWD's ICON-D2 model is a forecast model which is operated for the very-short range up to +27 hours (+45 hours for the 03 UTC run). Due to its fine mesh size, the ICON-D2 especially provides for improved forecasts of hazardous weather conditions, e.g. weather situations with high-level moisture convection (super and multi-cell thunderstorms, squall lines, mesoscale convective complexes) and weather events that are influenced by fine-scale topographic effects (ground fog, Föhn winds, intense downslope winds, flash floods). The model area of ICON-D2 covers the whole German territory, Benelux, Switzerland, Austria and parts of the other neighbouring countries at a horizontal resolution of 2.2 km. In the vertical, the model defines 65 atmosphere levels. The fairly short forecast periods make perfect sense because of the purpose of ICON-D2 (and its small model area). Based on model runs at 00, 06, 09, 12, 15, 18 and 21 UTC, ICON-D2 provides new 27-hour forecasts every 3 hours. The model run at 03 UTC even covers a forecast period of 45 hours. The ICON-D2 forecast data for each weather element are made available in standard packages at our free DWD Open Data Server, both on a rotated grid and on a regular grid. Regional ensemble forecast model ICON-D2 EPS The ensemble forecasting system ICON-D2 EPS is based on the DWD's numerical weather forecast model ICON-D2 and currently includes 20 ensemble members. All ensemble members are calculated at the same horizontal grid spacing as the operational configuration of ICON-D2 (2.2 km). Like ICON-D2, the ICON-D2 EPS ensemble system provides forecasts up to +27 hours for the same model area (up to +45 hours based on the 03 UTC run). For generating the ensemble members, some of the features of the forecasting system are changed. The method currently used to generate the ensemble members involves varying the - lateral boundary conditions - initial state - soil moisture - and model physics. For varying the lateral boundary conditions and the initial state, forecasts from various global models are used. The ICON-D2 EPS is provided on the DWD Open Data Server in the native triangular grid. Note: All previously COSMO-D2 based aviation weather products have been migrated to ICON-D2 on 10.02.2021. However, the familiar design of these products remains unchanged.
-
Overview: Vegetation tree species sample points Traceability (lineage): This is an original dataset produced with a machine learning framework which used a combination of point datasets and raster datasets as inputs. Point dataset is a harmonized collection of tree occurrence data, comprising observations from National Forest Inventories (EU-Forest), GBIF and LUCAS. The complete dataset is available on Zenodo. Raster datasets used as input are: harmonized and gapfilled time series of seasonal aggregates of the Landsat GLAD ARD dataset (bands and spectral indices); monthly time series air and surface temperature and precipitation from a reprocessed version of the Copernicus ERA5 dataset; long term averages of bioclimatic variables from CHELSA, tree species distribution maps from the European Atlas of Forest Tree Species; elevation, slope and other elevation-derived metrics; long term monthly averages snow probability and long term monthly averages of cloud fraction from MODIS. For a more comprehensive list refer to Bonannella et al. (2022) (in review, preprint available at: https://doi.org/10.21203/rs.3.rs-1252972/v1). Scientific methodology: Probability and uncertainty maps were the output of a spatiotemporal ensemble machine learning framework based on stacked regularization. Three base models (random forest, gradient boosted trees and generalized linear models) were first trained on the input dataset and their predictions were used to train an additional model (logistic regression) which provided the final predictions. More details on the whole workflow are available in the listed publication. Usability: Probability maps can be used to detect potential forest degradation and compositional change across the time period analyzed. Some possible applications for these topics are explained in the listed publication. Uncertainty quantification: Uncertainty is quantified by taking the standard deviation of the probabilities predicted by the three components of the spatiotemporal ensemble model. Data validation approaches: Distribution maps were validated using a spatial 5-fold cross validation following the workflow detailed in the listed publication. Completeness: The raster files perfectly cover the entire Geo-harmonizer region as defined by the landmask raster dataset available here. Consistency: Areas which are outside of the calibration area of the point dataset (Iceland, Norway) usually have high uncertainty values. This is not only a problem of extrapolation but also of poor representation in the feature space available to the model of the conditions that are present in this countries. Positional accuracy: The rasters have a spatial resolution of 30m. Temporal accuracy: The maps cover the period 2000 - 2020, each map covers a certain number of years according to the following scheme: (1) 2000--2002, (2) 2002--2006, (3) 2006--2010, (4) 2010--2014, (5) 2014--2018 and (6) 2018--2020 Thematic accuracy: Both probability and uncertainty maps contain values from 0 to 100: in the case of probability maps, they indicate the probability of occurrence of a single individual of the target species, while uncertainty maps indicate the standard deviation of the ensemble model.
-
331: Natural non-vegetated expanses of sand or pebble/gravel, in coastal or continental locations, like beaches, dunes, gravel pads; including beds of stream channels with torrential regime. Vegetation covers maximum 10%.
-
Overview: Actual Natural Vegetation (ANV): probability of occurrence for the Pedunculate oak in its realized environment for the period 2000 - 2033 Traceability (lineage): This is an original dataset produced with a machine learning framework which used a combination of point datasets and raster datasets as inputs. Point dataset is a harmonized collection of tree occurrence data, comprising observations from National Forest Inventories (EU-Forest), GBIF and LUCAS. The complete dataset is available on Zenodo. Raster datasets used as input are: harmonized and gapfilled time series of seasonal aggregates of the Landsat GLAD ARD dataset (bands and spectral indices); monthly time series air and surface temperature and precipitation from a reprocessed version of the Copernicus ERA5 dataset; long term averages of bioclimatic variables from CHELSA, tree species distribution maps from the European Atlas of Forest Tree Species; elevation, slope and other elevation-derived metrics; long term monthly averages snow probability and long term monthly averages of cloud fraction from MODIS. For a more comprehensive list refer to Bonannella et al. (2022) (in review, preprint available at: https://doi.org/10.21203/rs.3.rs-1252972/v1). Scientific methodology: Probability and uncertainty maps were the output of a spatiotemporal ensemble machine learning framework based on stacked regularization. Three base models (random forest, gradient boosted trees and generalized linear models) were first trained on the input dataset and their predictions were used to train an additional model (logistic regression) which provided the final predictions. More details on the whole workflow are available in the listed publication. Usability: Probability maps can be used to detect potential forest degradation and compositional change across the time period analyzed. Some possible applications for these topics are explained in the listed publication. Uncertainty quantification: Uncertainty is quantified by taking the standard deviation of the probabilities predicted by the three components of the spatiotemporal ensemble model. Data validation approaches: Distribution maps were validated using a spatial 5-fold cross validation following the workflow detailed in the listed publication. Completeness: The raster files perfectly cover the entire Geo-harmonizer region as defined by the landmask raster dataset available here. Consistency: Areas which are outside of the calibration area of the point dataset (Iceland, Norway) usually have high uncertainty values. This is not only a problem of extrapolation but also of poor representation in the feature space available to the model of the conditions that are present in this countries. Positional accuracy: The rasters have a spatial resolution of 30m. Temporal accuracy: The maps cover the period 2000 - 2020, each map covers a certain number of years according to the following scheme: (1) 2000--2002, (2) 2002--2006, (3) 2006--2010, (4) 2010--2014, (5) 2014--2018 and (6) 2018--2020 Thematic accuracy: Both probability and uncertainty maps contain values from 0 to 100: in the case of probability maps, they indicate the probability of occurrence of a single individual of the target species, while uncertainty maps indicate the standard deviation of the ensemble model.
-
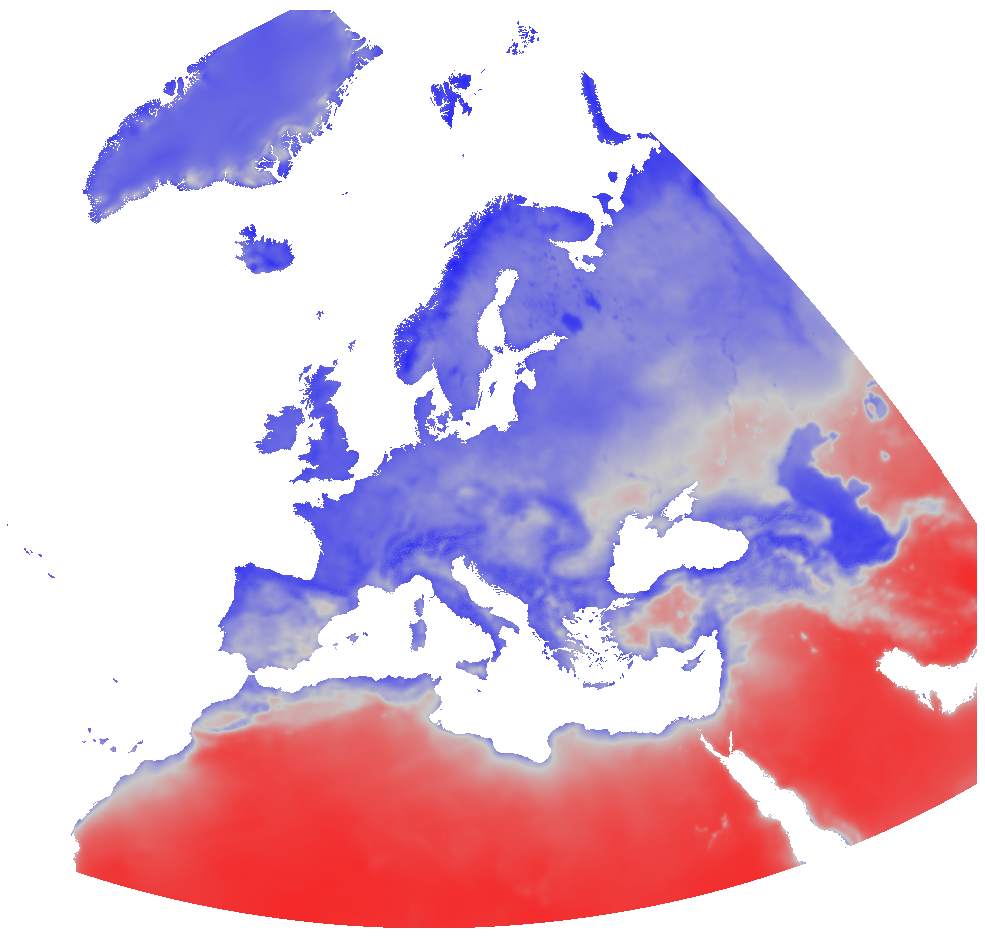
Overview: ERA5-Land is a reanalysis dataset providing a consistent view of the evolution of land variables over several decades at an enhanced resolution compared to ERA5. ERA5-Land has been produced by replaying the land component of the ECMWF ERA5 climate reanalysis. Reanalysis combines model data with observations from across the world into a globally complete and consistent dataset using the laws of physics. Reanalysis produces data that goes several decades back in time, providing an accurate description of the climate of the past. Processing steps: The original hourly ERA5-Land air temperature 2 m above ground and dewpoint temperature 2 m data has been spatially enhanced from 0.1 degree to 30 arc seconds (approx. 1000 m) spatial resolution by image fusion with CHELSA data (V1.2) (https://chelsa-climate.org/). For each day we used the corresponding monthly long-term average of CHELSA. The aim was to use the fine spatial detail of CHELSA and at the same time preserve the general regional pattern and fine temporal detail of ERA5-Land. The steps included aggregation and enhancement, specifically: 1. spatially aggregate CHELSA to the resolution of ERA5-Land 2. calculate difference of ERA5-Land - aggregated CHELSA 3. interpolate differences with a Gaussian filter to 30 arc seconds. 4. add the interpolated differences to CHELSA Subsequently, the temperature time series have been aggregated on a daily basis. From these, daily relative humidity has been calculated for the time period 01/2000 - 07/2021. Relative humidity (rh2m) has been calculated from air temperature 2 m above ground (Ta) and dewpoint temperature 2 m above ground (Td) using the formula for saturated water pressure from Wright (1997): maximum water pressure = 611.21 * exp(17.502 * Ta / (240.97 + Ta)) actual water pressure = 611.21 * exp(17.502 * Td / (240.97 + Td)) relative humidity = actual water pressure / maximum water pressure The resulting relative humidity has been aggregated to decadal averages. Each month is divided into three decades: the first decade of a month covers days 1-10, the second decade covers days 11-20, and the third decade covers days 21-last day of the month. Resultant values have been converted to represent percent * 10, thus covering a theoretical range of [0, 1000]. The data have been reprojected to EU LAEA. File naming scheme (YYYY = year; MM = month; dD = number of decade): ERA5_land_rh2m_avg_decadal_YYYY_MM_dD.tif Projection + EPSG code: EU LAEA (EPSG: 3035) Spatial extent: north: 6874000 south: -485000 west: 869000 east: 8712000 Spatial resolution: 1000 m Temporal resolution: Decadal Pixel values: Percent * 10 (scaled to Integer; example: value 738 = 73.8 %) Software used: GDAL 3.2.2 and GRASS GIS 8.0.0 Original ERA5-Land dataset license: https://apps.ecmwf.int/datasets/licences/copernicus/ CHELSA climatologies (V1.2): Data used: Karger D.N., Conrad, O., Böhner, J., Kawohl, T., Kreft, H., Soria-Auza, R.W., Zimmermann, N.E, Linder, H.P., Kessler, M. (2018): Data from: Climatologies at high resolution for the earth's land surface areas. Dryad digital repository. http://dx.doi.org/doi:10.5061/dryad.kd1d4 Original peer-reviewed publication: Karger, D.N., Conrad, O., Böhner, J., Kawohl, T., Kreft, H., Soria-Auza, R.W., Zimmermann, N.E., Linder, P., Kessler, M. (2017): Climatologies at high resolution for the Earth land surface areas. Scientific Data. 4 170122. https://doi.org/10.1038/sdata.2017.122 Processed by: mundialis GmbH & Co. KG, Germany (https://www.mundialis.de/) Reference: Wright, J.M. (1997): Federal meteorological handbook no. 3 (FCM-H3-1997). Office of Federal Coordinator for Meteorological Services and Supporting Research. Washington, DC Acknowledgements: This study was partially funded by EU grant 874850 MOOD. The contents of this publication are the sole responsibility of the authors and don't necessarily reflect the views of the European Commission.
-
Overview: Actual Natural Vegetation (ANV): probability of occurrence for the Austrian pine in its realized environment for the period 2000 - 2027 Traceability (lineage): This is an original dataset produced with a machine learning framework which used a combination of point datasets and raster datasets as inputs. Point dataset is a harmonized collection of tree occurrence data, comprising observations from National Forest Inventories (EU-Forest), GBIF and LUCAS. The complete dataset is available on Zenodo. Raster datasets used as input are: harmonized and gapfilled time series of seasonal aggregates of the Landsat GLAD ARD dataset (bands and spectral indices); monthly time series air and surface temperature and precipitation from a reprocessed version of the Copernicus ERA5 dataset; long term averages of bioclimatic variables from CHELSA, tree species distribution maps from the European Atlas of Forest Tree Species; elevation, slope and other elevation-derived metrics; long term monthly averages snow probability and long term monthly averages of cloud fraction from MODIS. For a more comprehensive list refer to Bonannella et al. (2022) (in review, preprint available at: https://doi.org/10.21203/rs.3.rs-1252972/v1). Scientific methodology: Probability and uncertainty maps were the output of a spatiotemporal ensemble machine learning framework based on stacked regularization. Three base models (random forest, gradient boosted trees and generalized linear models) were first trained on the input dataset and their predictions were used to train an additional model (logistic regression) which provided the final predictions. More details on the whole workflow are available in the listed publication. Usability: Probability maps can be used to detect potential forest degradation and compositional change across the time period analyzed. Some possible applications for these topics are explained in the listed publication. Uncertainty quantification: Uncertainty is quantified by taking the standard deviation of the probabilities predicted by the three components of the spatiotemporal ensemble model. Data validation approaches: Distribution maps were validated using a spatial 5-fold cross validation following the workflow detailed in the listed publication. Completeness: The raster files perfectly cover the entire Geo-harmonizer region as defined by the landmask raster dataset available here. Consistency: Areas which are outside of the calibration area of the point dataset (Iceland, Norway) usually have high uncertainty values. This is not only a problem of extrapolation but also of poor representation in the feature space available to the model of the conditions that are present in this countries. Positional accuracy: The rasters have a spatial resolution of 30m. Temporal accuracy: The maps cover the period 2000 - 2020, each map covers a certain number of years according to the following scheme: (1) 2000--2002, (2) 2002--2006, (3) 2006--2010, (4) 2010--2014, (5) 2014--2018 and (6) 2018--2020 Thematic accuracy: Both probability and uncertainty maps contain values from 0 to 100: in the case of probability maps, they indicate the probability of occurrence of a single individual of the target species, while uncertainty maps indicate the standard deviation of the ensemble model.
-

Temperature time series with high spatial and temporal resolutions are important for several applications. The new MODIS Land Surface Temperature (LST) collection 6 provides numerous improvements compared to collection 5. However, being remotely sensed data in the thermal range, LST shows gaps in cloud-covered areas. With a novel method [1] we fully reconstructed the daily global MODIS LST products MOD11C1 and MYD11C1 (spatial resolution: 3 arc-min, i.e. approximately 5.6 km at the equator). For this, we combined temporal and spatial interpolation, using emissivity and elevation as covariates for the spatial interpolation. Here we provide a time series of these reconstructed LST data aggregated as monthly average, minimum and maximum LST maps. [1] Metz M., Andreo V., Neteler M. (2017): A new fully gap-free time series of Land Surface Temperature from MODIS LST data. Remote Sensing, 9(12):1333. DOI: http://dx.doi.org/10.3390/rs9121333 The data available here for download are the reconstructed global MODIS LST products MOD11C1/MYD11C1 at a spatial resolution of 3 arc-min (approximately 5.6 km at the equator; see https://lpdaac.usgs.gov/dataset_discovery/modis/modis_products_table), aggregated to monthly data. The data are provided in GeoTIFF format. The Coordinate Reference System (CRS) is identical to the MOD11C1/MYD11C1 product as provided by NASA. In WKT as reported by GDAL: GEOGCS["Unknown datum based upon the Clarke 1866 ellipsoid", DATUM["Not specified (based on Clarke 1866 spheroid)", SPHEROID["Clarke 1866",6378206.4,294.9786982138982, AUTHORITY["EPSG","7008"]]], PRIMEM["Greenwich",0], UNIT["degree",0.0174532925199433]] Acknowledgments: We are grateful to the NASA Land Processes Distributed Active Archive Center (LP DAAC) for making the MODIS LST data available. The dataset is based on MODIS Collection V006. File name abbreviations: avg = average of daily averages min = minimum of daily minima max = maximum of daily maxima Meaning of pixel values: The pixel values are coded in degree Celsius * 100 (hence, to obtain °C divide the pixel values by 100.0).
-
Overview: Potential Natural Vegetation (PNV): potential probability of occurrence for the Olive tree from 2018 to 2020 Traceability (lineage): This is an original dataset produced with a machine learning framework which used a combination of point datasets and raster datasets as inputs. Point dataset is a harmonized collection of tree occurrence data, comprising observations from National Forest Inventories (EU-Forest), GBIF and LUCAS. The complete dataset is available on Zenodo. Raster datasets used as input are: monthly time series air and surface temperature and precipitation from a reprocessed version of the Copernicus ERA5 dataset; long term averages of bioclimatic variables from CHELSA; elevation, slope and other elevation-derived metrics and long term monthly averages snow probability. For a more comprehensive list refer to Bonannella et al. (2022) (in review, preprint available at: https://doi.org/10.21203/rs.3.rs-1252972/v1). Scientific methodology: Probability and uncertainty maps were the output of a spatiotemporal ensemble machine learning framework based on stacked regularization. Three base models (random forest, gradient boosted trees and generalized linear models) were first trained on the input dataset and their predictions were used to train an additional model (logistic regression) which provided the final predictions. More details on the whole workflow are available in the listed publication. Usability: Probability maps are particularly useful when compared with existing products of potential distribution of species or when combined with maps of realized distribution: gaps in potential and realized distribution can be identified and used as information for future programs of tree planting or forest restoration. Uncertainty quantification: Uncertainty is quantified by taking the standard deviation of the probabilities predicted by the three components of the spatiotemporal ensemble model. Data validation approaches: Distribution maps were validated using a spatial 5-fold cross validation following the workflow detailed in the listed publication. Completeness: The raster files perfectly cover the entire Geo-harmonizer region as defined by the landmask raster dataset available here. Consistency: Areas which are outside of the calibration area of the point dataset (Iceland, Norway) usually have high uncertainty values. This is not only a problem of extrapolation but also of poor representation in the feature space available to the model of the conditions that are present in this countries. Positional accuracy: The rasters have a spatial resolution of 30m. Temporal accuracy: The maps cover the period 2018 - 2020 Thematic accuracy: Both probability and uncertainty maps contain values from 0 to 100: in the case of probability maps, they indicate the probability of occurrence of a single individual of the target species, while uncertainty maps indicate the standard deviation of the ensemble model.
-
Areas planted with vines, vineyard parcels covering >50% and determining the land use of the area.
-
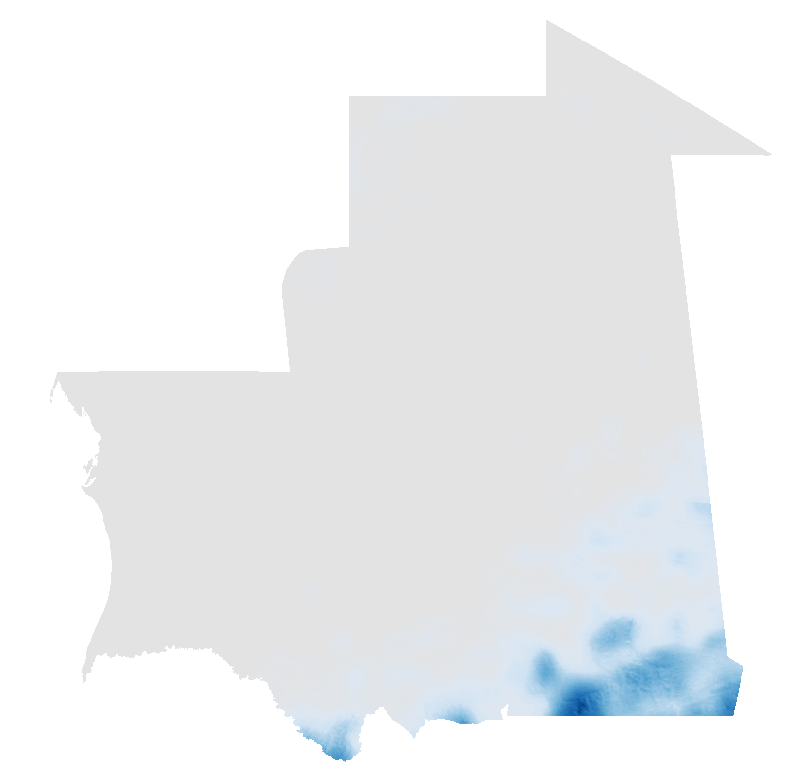
ERA5-Land total precipitation monthly time series for Mauritania at 30 arc seconds (ca. 1000 meter) resolution (2019 - 2023) Source data: ERA5-Land is a reanalysis dataset providing a consistent view of the evolution of land variables over several decades at an enhanced resolution compared to ERA5. ERA5-Land has been produced by replaying the land component of the ECMWF ERA5 climate reanalysis. Reanalysis combines model data with observations from across the world into a globally complete and consistent dataset using the laws of physics. Reanalysis produces data that goes several decades back in time, providing an accurate description of the climate of the past. Total precipitation: Accumulated liquid and frozen water, including rain and snow, that falls to the Earth's surface. It is the sum of large-scale precipitation (that precipitation which is generated by large-scale weather patterns, such as troughs and cold fronts) and convective precipitation (generated by convection which occurs when air at lower levels in the atmosphere is warmer and less dense than the air above, so it rises). Precipitation variables do not include fog, dew or the precipitation that evaporates in the atmosphere before it lands at the surface of the Earth. This variable is accumulated from the beginning of the forecast time to the end of the forecast step. The units of precipitation are depth in metres. It is the depth the water would have if it were spread evenly over the grid box. Care should be taken when comparing model variables with observations, because observations are often local to a particular point in space and time, rather than representing averages over a model grid box and model time step. Processing steps: The original hourly ERA5-Land data has been spatially enhanced from 0.1 degree to 30 arc seconds (approx. 1000 m) spatial resolution by image fusion with CHELSA data (V1.2) (https://chelsa-climate.org/). For each day we used the corresponding monthly long-term average of CHELSA. The aim was to use the fine spatial detail of CHELSA and at the same time preserve the general regional pattern and fine temporal detail of ERA5-Land. The steps included aggregation and enhancement, specifically: 1. spatially aggregate CHELSA to the resolution of ERA5-Land 2. calculate proportion of ERA5-Land / aggregated CHELSA 3. interpolate proportion with a Gaussian filter to 30 arc seconds 4. multiply the interpolated proportions with CHELSA Using proportions ensures that areas without precipitation remain areas without precipitation. Only if there was actual precipitation in a given area, precipitation was redistributed according to the spatial detail of CHELSA. The spatially enhanced daily ERA5-Land data has been aggregated to monthly resolution, by calculating the sum of the precipitation per pixel over each month. File naming: ERA5_land_monthly_prectot_sum_30sec_YYYY_MM_01T00_00_00_int.tif e.g.:ERA5_land_monthly_prectot_sum_30sec_2023_12_01T00_00_00_int.tif The date within the filename is year and month of aggregated timestamp. Pixel values: mm * 10 Scaled to Integer, example: value 218 = 21.8 mm Projection + EPSG code: Latitude-Longitude/WGS84 (EPSG: 4326) Spatial extent: north: 28:18N south: 14:42N west: 17:05W east: 4:49W Temporal extent: January 2019 - December 2023 Spatial resolution: 30 arc seconds (approx. 1000 m) Temporal resolution: monthly Lineage: Dataset has been processed from original Copernicus Climate Data Store (ERA5-Land) data sources. As auxiliary data CHELSA climate data has been used. Software used: GRASS GIS 8.3.2 Format: GeoTIFF Original ERA5-Land dataset license: https://cds.climate.copernicus.eu/api/v2/terms/static/licence-to-use-copernicus-products.pdf CHELSA climatologies (V1.2): Data used: Karger D.N., Conrad, O., Böhner, J., Kawohl, T., Kreft, H., Soria-Auza, R.W., Zimmermann, N.E, Linder, H.P., Kessler, M. (2018): Data from: Climatologies at high resolution for the earth's land surface areas. Dryad digital repository. http://dx.doi.org/doi:10.5061/dryad.kd1d4 Original peer-reviewed publication: Karger, D.N., Conrad, O., Böhner, J., Kawohl, T., Kreft, H., Soria-Auza, R.W., Zimmermann, N.E., Linder, P., Kessler, M. (2017): Climatologies at high resolution for the Earth land surface areas. Scientific Data. 4 170122. https://doi.org/10.1038/sdata.2017.122 Representation type: Grid Processed by: mundialis GmbH & Co. KG, Germany (https://www.mundialis.de/) Contact: mundialis GmbH & Co. KG, info@mundialis.de Acknowledgements: This study was partially funded by EU grant 874850 MOOD. The contents of this publication are the sole responsibility of the authors and don't necessarily reflect the views of the European Commission.